前回の続編です。
前回はWebサイト1ページからスクレイピングをしましたが、今回は1~3ページからスクレイピングをしてみたいと思います。
どういうものかと説明すると、こちらの横浜イベントサイトの↓
https://hamakore.yokohama/event/
先頭3ページ分の記事タイトルの中で、「赤レンガ倉庫」「山下公園」という文字を含むタイトルだけを抜き出しエクセルファイル(CSV)に保存するというものです↓

Webサイト3ページ分スクレイピングしてみた。
前回の記事のコードをもとに、3ページ分記事タイトルをスクレイピングするコードを考えました。
ちょっと難しかったですが、手順としてはこうです。
- 最初に空のリストを作る(あとでpandasのDataFrameオブジェクトを作るのに必要)。
- for文で3ページ分回す。
- for文の中でさらにfor文を回し、取得したタイトル一つ一つを空のリストに入れていく。
- 取得した複数のタイトルが入ったリストをDataFrameオブジェクトにして、to_csvメソッドでエクセルファイルに保存する。
コードはこうです↓
import re
import requests
from bs4 import BeautifulSoup
import time
from urllib.parse import urljoin
import pandas as pd
url='https://hamakore.yokohama/event/'
# 空のリストを作る(DataFrameオブジェクトにするのに必要)
title_list=[]
# 1~3ページ分のタイトルを取得
for i in range(1,4):
# 1ページ目はそのままのURL
if i==1:
page_url=url
else:
# 2ページ以降はURLをつなげる
page_url=urljoin(url,f'page/{i}')
# 1~3ページのそれぞれのURLにアクセス
res=requests.get(page_url)
soup=BeautifulSoup(res.text,'html.parser')
# 「赤レンガ倉庫」「山下公園」を含むタイトルをしゅとくする
pattern=re.compile('赤レンガ倉庫|山下公園')
titles=soup.find_all('div',class_='articletitle',string=pattern)
for title in titles:
# 空のリストにタイトルを入れていく
title_list.append(title.text)
time.sleep(1)
print(title_list)
# csvで保存するためにDataFrameオブジェクトにする
df=pd.DataFrame(title_list,columns=['タイトル'])
# csvで保存する
df.to_csv('minatomirai-3pages.csv',index=False,encoding='utf-8-sig')
実行すると、できました!
エクセルファイルが作成され↓
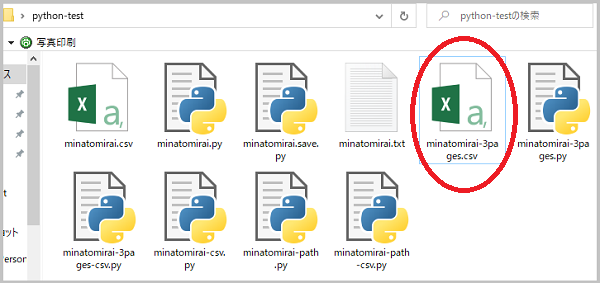
ファイルを開くと↓
うまくいってます。
どうでしょうか?「Webサイトの複数ページから、ある文字を含む要素を抜き出しエクセルファイルにまとめる」というのは結構使えそうですよね。
ぜひ参考にしてみてください。
はい、これでこの本で勉強したことはだいぶ身に付いたかなと思います↓

この本には他にも、データを整理・加工したり、集計したり、グラフ化したり、様々なことが載っていますが、アウトプットするのはこのへんで終わりにしたいと思います。
「Python 自動処理の教科書」を買った。
そして、「Python 自動処理の教科書」を買いました。

この本はPython自動化においてはかなり有名で、知っている人も多いのではないでしょうか。
「Pythonでエクセルやメール、ツイッター、LINEを自動化したい」という方にはオススメです。
ただかなり分厚いです。
この本に書いてあることを全てパソコンでやるのはそうとうな時間がかかるので、この本はざっと流し読みすればいいと思ってます。
どんなことが出来るのかがわかっていれば、必要になった時にこの本を見ながらできる。
次回はこの本の感想になるかと思います。

