
この本↓で勉強したことを使って、実際にWebスクレイピングをやってみました。

まず、どんなことをやったか結果をお見せします。
この横浜イベント情報のWebサイトから↓
https://hamakore.yokohama/event/
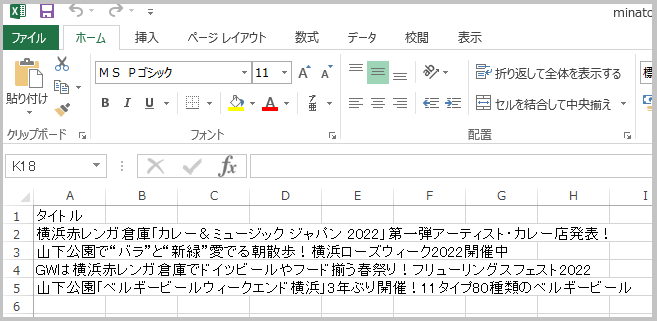
「赤レンガ倉庫」「山下公園」の文字が含まれるタイトルだけを抜き出し、エクセルファイル(CSV)に保存するというもの↓
基本的に本に書いてある内容でできますが、そのままのやり方ではできないので考え方には少し応用が必要です。
どのようにやったか手順を書いていきます。
そのWebサイトでスクレイピングが禁止されていないか確認。
まず、そのWebサイトでスクレイピングが禁止されていないか確認。
確認方法はこちらの記事で書いてます↓

今回のWebサイトでは特に禁止はされていないようでした。
WebサイトのHTMLを、ファイルに保存。
いきなりWebサイトからスクレイピングしてもいいのですが、最初は絶対エラーが出るし、何度もアクセスするとWebサイトに迷惑がかかってしまうので、
まずWebサイトのHTMLをファイルに保存し、そのファイルをスクレイピングしテストします。
WebサイトのHTMLをファイルに保存するには、write_textメソッドを使います。
コードはこうです↓
from pathlib import Path
import requests
url='https://hamakore.yokohama/event/'
res=requests.get(url)
rfile=Path('minatomirai.txt')
# 「minatomirai.txt」というテキストファイルで保存する
rfile.write_text(res.text,encoding='utf-8')
「minatomirai.txt」というファイルが保存されました↓
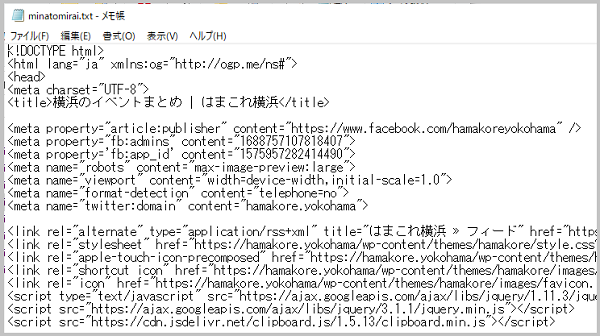
ファイルを開くと↓
保存したファイルからスクレイピング
保存できたminatomirai.txtファイルからスクレイピングしていきます。
コードはこうです↓
import re
from pathlib import Path
from bs4 import BeautifulSoup
hfile=Path('minatomirai.txt')
htext=hfile.read_text(encoding='utf-8')
soup=BeautifulSoup(htext,'html.parser')
# 「赤レンガ」と「山下公園」を含むタイトルを探す
pattern=re.compile('赤レンガ倉庫|山下公園')
titles=soup.find_all('div',class_='articletitle',string=pattern)
for title in titles:
print(title.text)
「赤レンガ倉庫」「山下公園」が含まれるタイトルがうまく取得できてます↓
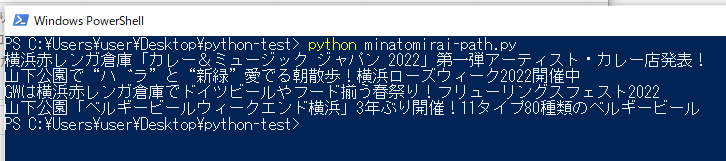
エクセルファイル(CSV)に保存。pandas DataFrameオブジェクトのcolumnsが一行の場合の書き方は?
取得できたタイトルをエクセルファイル(CSV)に保存します。
エクセルファイル(CSV)に保存するには、pandasのto_csvメソッドを使います。
本だとエクセルファイルが2行なので、DataFrameオブジェクトの引数「columns」のところが
columns=[‘行タイトル1’,’行タイトル2’]
となっていたのですが、
「1行の場合columnsはどう書くんだろう?」と調べた結果、
columns=[‘行タイトル’]でいいことがわかりました。
コードはこうです↓
import re
from pathlib import Path
from bs4 import BeautifulSoup
import pandas as pd
hfile=Path('minatomirai.txt')
htext=hfile.read_text(encoding='utf-8')
soup=BeautifulSoup(htext,'html.parser')
pattern=re.compile('赤レンガ倉庫|山下公園')
titles=soup.find_all('div',class_='articletitle',string=pattern)
# 空のリストを作る(DataFrameオブジェクトにするのに必要)
title_list=[]
for title in titles:
# 空のリストにタイトルを入れていく
title_list.append(title.text)
print(title_list)
# csvで保存するためにDataFrameオブジェクトにする
df=pd.DataFrame(title_list,columns=['タイトル'])
# csvで保存する
df.to_csv('minatomirai.csv',index=False,encoding='utf-8-sig')
「minatomirai.csv」というエクセルファイルが保存できました↓
ファイルを開くと↓
実際のWebサイトからスクレイピング。
テスト(ファイルからのスクレイピング)がうまくいったので、今度は実際のWebサイトからスクレイピングしていきます。
さきほどのコードのPathオブジェクトのところを、requestsに変えるだけです↓
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
url='https://hamakore.yokohama/event/'
res=requests.get(url)
soup=BeautifulSoup(res.text,'html.parser')
pattern=re.compile('赤レンガ倉庫|山下公園')
titles=soup.find_all('div',class_='articletitle',string=pattern)
title_list=[]
for title in titles:
# 空のリストにタイトルを入れていく
title_list.append(title.text)
print(title_list)
# csvで保存するためにDataFrameオブジェクトにする
df=pd.DataFrame(title_list,columns=['タイトル'])
# csvで保存する
df.to_csv('minatomirai.csv',index=False,encoding='utf-8-sig')
先程と同じようにできました!↓
これで今回は完了です。
いかがでしたでしょうか?
「Webサイトから、ある文字を含む要素を抜き出してエクセルファイルに保存する」というのは、結構使えるのではないでしょうか。
今回はWebサイトの1ページのみでしたが、次回は複数ページからスクレイピングしてみたいと思います。

